

Intro
Instalación desde cero de un nuevo cluster de HA empleando pacemaker, corosync y drbd
Características de los servidores
Particiones:
- 200 MB /boot/efi
- 500 MB /boot
- 50 GB /
- 36 GB swap
ext4
Kernel
3.16
drbd
drbd8.4.8-1
drbd8.4.9-1
drbd-utils8.9.8
drbd-utils8.9.10
Instalación
- Servidor de infraestructura
- Alta disponibilidad
- Almacenamiento resistente
- Hipervisor de virtualización
Post-instalación
Generamos la clave rsa:
#ssh-keygen -t rsa -b 8191
Nombrar nodo:
# hostnamectl set-hostname cectnode21 --static
Actualizamos el SO
# yum update
Problemas conocidos
En una de las actualizaciones de seguridad, RedHat (o CentOS) liberó la versión 10:1.5.3-105.el7_2.7 de los paquetes qemu que teníamos instalados (qemu-img, qemu-kvm y qemu-kvm-common). Esta actualización provocó (nos dimos cuenta después de casi un mes de quebraderos de cabeza) que las máquinas no migrasen en caliente entre los nodos del cluster. Solamente migraba en caliente el Windows Server 2012r2.
Para evitar este problema deberemos de actuar del siguente modo. Puesto que la versión base de las herramientas qemu ha sufrido actualizaciones «funcionales», no tiene sentido que mantengamos la versión base instalada. Sin embargo si actualizamos sin más, el sistema instalará la versión que no funciona en el cluster. Puesto que la última versión que funcionaba era la 10:1.5.3-105.el7_2.4, para instalar ésta haremos:
Eliminar las versiones anteriores de qemu*:
# yum remove qemu*
Como resultado también nos elimina los paquetes de libvirt, libvirt-daemon-driver-qemu y libvirt-daemon-driver-storage. Los instalaremos luego.
Instalamos la versión el7_2.4 de los paquetes qemu:
# yum install qemu-img-1.5.3-105.el7_2.4
# yum install qemu-kvm-1.5.3-105.el7_2.4
También instala como dependencia el tercer paquete: qemu-kvm-common
Instalar los paquetes de libvirt
# yum install libvirt
Instala libvirt y como dependencias también los otros dos paquetes que había desinstalado.
Intercambiamos las clave de root entre los nodos:
Las copiamos en authorized_keys del otro nodo y luego copiamos el authorized_keys para que sea el mismo
Configuramos el bond con las interfaces de 10000MB:
Ver el siguiente tutorial:
Instalar y configurar 4xGB Eth en nodos
Configuramos las IP de gestión
node1: 192.168.26.1
node2: 192.168.26.2
Desactivar SELINUX y firewall
/etc/sysconfig/selinux
# systemctl disable firewalld
# systemctl stop firewalld
Configuramos pacemaker
# systemctl start pcsd.service
# systemctl enable pcsd.service
Ponemos la contraseña al usuario hacluster:
# echo nuevo_passwd | passwd --stdin hacluster
Inicializamos el cluster:
En ambos nodos:
# pcs cluster auth node1 node2 -u hacluster
Iniciamos la comunicación:
En un solo nodo:
# pcs cluster setup --name micluster node1 node2
Modificamos el archivo /etc/corosync/corosync.conf:
Si queremos encriptar la comunicación entre los nodos:
- Comentamos secauth: off
- Añadimos en totem:
crypto_cipher: aes256crypto_hash: sha512
Comentamos transport: udpu
Agregamos en quorum:
wait_for_all: 0
Modificamos en logging:
to_syslog: no
En un solo nodo generamos la clave para comunicarse ambos nodos:
# corosync-keygen
La copiamos al otro:
# scp /etc/corosync/authkey node2:/etc/corosync/
Iniciamos el cluster:
En uno de los nodos:
# pcs cluster start --all
Comprobamos en los dos nodos como va:
#pcs status
Deshabilitamos el quorum
Al tratarse de un cluster de dos nodos, si no deshabilitamos el quorum, al fallar cualquiera de los nodos se perdería el quorum y se pararí3an todos los servicios.
# pcs property set no-quorum-policy=ignore
Para comprobar que se ha deshabilitado, hacemos:
# pcs property
Configuramos el fencing
Nosotros utilizaremos el ilo4. Tratamos de configurar, aunque sin exito el ilo4_ssh
drbd
drbd-utils-8.9.10
Configuramos con las siguientes opciones:
# ./configure --prefix=/usr --localstatedir=/var --sysconfdir=/etc --without-83support --with-pacemaker
En la versión 8.9.8 el sistema arrojaba un error en la compilación de la documentación. Se quejaba de que no podía compilar algunos xml de docbook.sourceforge.net
Para solucionar el problema instalamos el paquete docbook-utils.noarch
El problema se soluciona en la versión 8.9.9
Tras compilar, instalamos con make install
Kernel
Instalamos el 3.16
(3.16.39)
Una vez instalado (make && make modules_install && make install), tenemos que asegurarnos que el sistema arranca con el kernel nuevo.
En alguna ocasión no existía el archivo /boot/grub2/grub.cfg y para generarlo hubo que ejecutar el siguiente comando:
# grub2-mkconfig -o /boot/grub2/grub.cfg
Luego buscamos el kernel recién instalado con:
# grep menuentry /boot/grub2/grub.cfg
En nuestro caso, nos interesa la línea:
menuentry 'CentOS Linux (3.16.39) 7 (Core)'
Ponemos este kernel por defecto:
# grub2-set-default 'CentOS Linux (3.16.39) 7 (Core)'
Y reiniciamos la máquina.
Compilamos el módulo drbd
Como ya estamos corriendo el kernel correcto, para generar el módulo nos vale entrar en el directorio fuente de drbd y hacer:
# make && make install
Sin embargo, para asegurarnos de que todo va bien hacemos:
# make KDIR=/lib/modules/3.16.39/build
# make install
Comprobamos que está funcionando correctamente con
# modprobe drbd
Para ver la información de drbd hacemos:
# drbdadm --version
DRBDADM_BUILDTAG=GIT-hash:\ 54df7406bd33851eb5fdde48362754bfd71e0500\ build\ by\ root@cectnode2\,\ 2017-01-12\ 12:59:14
DRBDADM_API_VERSION=1
DRBD_KERNEL_VERSION_CODE=0x080409
DRBDADM_VERSION_CODE=0x08090a
DRBDADM_VERSION=8.9.10
Recursos
Recurso drbd datos
Creamos el recurso de acuerdo a las instrucciones del libro de clusters y lo forzamos como primario en uno de los nodos, con lo que comienza la transferencia de datos para sincronizar las particiones de ambos nodos.
Comprobamos que cuando ponemos uno de los nodos en primary comienza la sincronización, aunque la velocidad de ésta hace que el proceso se pueda eternizar. En nuestro caso la velocidad era de 1,4K/sec
En el artículo ‘Configuring the rate of syncronization’ de la guía de drbd 8.4 nos dan la clave para acelerar el proceso:
# drbdadm disk-options --c-plan-ahead=0 --resync-rate=33M datos
Esto habría que hacerlo en el nodo que recibe los datos, el SyncTarget node. La velocidad de transferencia superó los 30M/sec
Para devolver los valores de velocidad de tranferencia a los que tiene por defecto en el archivo de configuración hacemos:
# drbdadm adjust datos
DLM y GFS2
En nuestro caso hemos decidido no montar LVM ya que añade un nivel de complejidad y un punto de fallo y sin embargo no nos proporciona ningún beneficio extraordinario.
Iniciamos el servicio DLM, pero para eso ha de estar iniciado el cluster. Lo comprobamos con:
# pcs status
Si no está corriendo ejecutamos (en ambos nodos o al menos en aquel donde no esté ejecutándose el servicio de cluster):
# pcs cluster start
Ahora iniciamos el servicio dlm (en ambos nodos):
# systemctl start dlm.service
# clvmd
Arrancamos drbd en ambos nodos, cargamos el recurso compartido y ponemos los dos nodos como primarios:
# modprobe drbd
# drbdadm up datos
# drbdadm primary datos
Formateamos el dispositivo /dev/drbd0 como gfs2 (en un nodo):
# mkfs.gfs2 -p lock_dlm -j 2 -t microkuster:datos /dev/drbd0
Probamos que funciona montando /dev/drbd0 en /home/datos en ambos nodos y creando un directorio dentro de /home/datos en uno de los nodos. En el otro nodo deberíamos ver ese directorio.
Crear el recurso drbd en el cluster
Para ello ejecutamos los siguientes comandos:
# pcs cluster cib drbd_cf
# pcs -f drbd_cf resource create drbd_datos ocf:linbit:drbd drbd_resource=datos op monitor interval=60s
# pcs -f drbd_cf resource master drbd_datos-clone drbd_datos master-max=2 master-node-max=1 clone-max=2 clone-node-max=1 notify=true
# pcs cluster cib-push drbd_cf
Crear recurso dlm
Mediante los siguientes comandos:
# pcs cluster cib dlm_cf
# pcs -f dlm_cf resource create dlm ocf:pacemaker:controld op monitor interval=60s
# pcs -f dlm_cf resource clone dlm clone-max=2 clone-node-max=1
# pcs cluster cib-push dlm_cf
Crear el recurso del sistema de ficheros
# pcs cluster cib fs_cf
# pcs -f fs_cf resource create sharedFS Filesystem device="/dev/drbd0" directory="/home/datos" fstype="gfs2"
# pcs -f fs_cf resource clone sharedFS clone-max=2 clone-node-max=1
# pcs cluster cib-push fs_cf
Configurando las restricciones
# pcs cluster cib r_cf
# pcs -f r_cf constraint order start dlm-clone then promote drbd_datos-clone
Adding dlm-clone drbd_datos-clone (kind: Mandatory) (Options: first-action=start then-action=promote)
# pcs -f r_cf constraint order promote drbd_datos-clone then start sharedFS-clone kind=Serialize
Adding drbd_datos-clone sharedFS-clone (kind: Serialize) (Options: first-action=promote then-action=start)
# pcs -f r_cf constraint colocation add master drbd_datos-clone with dlm-clone
# pcs -f r_cf constraint colocation add sharedFS-clone with master drbd_datos-clone
# pcs cluster cib-push r_cf
Crear el recurso libvirtd
# pcs cluster cib lv_cf
# pcs -f lv_cf resource create res_libvirtd systemd:libvirtd op start interval=0s timeout=15s stop interval=0s timeout=15s monitor interval=15s timeout=15s
# pcs -f lv_cf resource clone res_libvirtd clone-max=2 notify=true
# pcs cluster cib-push lv_cf
Puesto que queremos que sea el cluster quien inicie libvirtd y el sistema lo tiene activado por defecto, deberemos desactivar libvirtd al inicio con el comando:
# systemctl disable libvirtd
Sus restricciones
# pcs cluster cib rl_cf
# pcs -f rl_cf constraint order start sharedFS-clone then start res_libvirtd-clone kind=Serialize
Adding sharedFS-clone res_libvirtd-clone (kind: Serialize) (Options: first-action=start then-action=start)
# pcs -f rl_cf constraint colocation add res_libvirtd-clone sharedFS-clone
# pcs cluster cib-push rl_cf
Máquinas virtuales
Una vez hemos creado una máquina virtual con virt-manager y tenemos el archivo de configuración xml en el directorio /home/datos/xmls, procederemos a crear el recurso correspondiente:
# pcs cluster cib mv_cf
# pcs -f mv_cf resource create c7test ocf:heartbeat:VirtualDomain hypervisor="qemu:///system" config="/home/datos/xmls/centos7.0.xml" migration_transport=ssh meta allow-migrate=true
# pcs cluster cib-push mv_cf
Sus restricciones
# pcs cluster cib r_mv
# pcs -f r_mv constraint order start res_libvirtd-clone then start c7test symmetrical=false
# pcs cluster cib-push r_mv
Migración en caliente de las máquinas virtuales
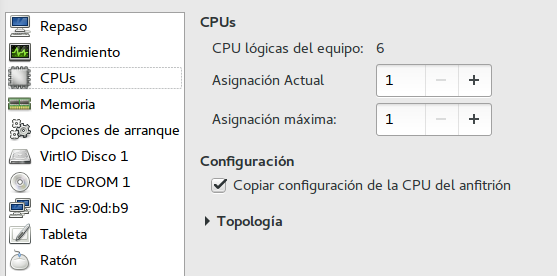
Con la versión actual de qemu la migración en caliente de las máquinas virtuales falla salvo que tengamos clicada la opción ‘Copiar la configuración de la CPU del anfitrión’ en el virt-manager (fig. 1). Con esta opción sin clicar apaga las máquinas virtuales antes de migrarlas. Si queremos modificar el valor correspondiente en el archivo xml generado sin pasar por la interfaz del virt-manager debemos añadir lo siguiente tras la entrada ‘</features>’, antes del nodo del clock:
<cpu mode='host-model'>
<model fallback='allow'/>
</cpu>
Versión de qemu:
# virsh version
Compilada con biblioteca: libvirt 2.0.0
Uso de biblioteca: libvirt 2.0.0
Utilizando API: QEMU 2.0.0
Ejecutando hypervisor: QEMU 1.5.3
A veces resulta necesario aumentar el timeout para la migración en caliente de las máquinas virtuales, sobre todo si tienen asignada gran cantidad de memoria y están muy cargadas. Con proxmox pasa siempre. Para aumentar el timeout en la migración haremos:
# pcs resource op add cectmox4_3.4 migrate_to interval=0s timeout=180s
# pcs resource op add cectmox4_3.4 migrate_from interval=0s timeout=180s
NFS server
Para poder compartir los archivos directamente del volumen drbd en lugar de hacerlo en un disco duro virtual de una máquina empleamos NFS
# pcs cluster cib nfs_cf
# pcs -f nfs_cf resource create res_nfs-server systemd:nfs-server op start interval=0s timeout=15s stop interval=0s timeout=15s monitor interval=15s timeout=15s
# pcs -f nfs_cf resource clone res_nfs-server clone-max=2 notify=true
# pcs cluster cib-push nfs_cf
Sus restricciones
Es necesario que se haya iniciado sharedFS-clone para poder exportar los recursos compartidos
# pcs cluster cib r_nfs
# pcs -f r_nfs constraint order start sharedFS-clone then start res_nfs-server-clone kind=Serialize
# pcs -f r_nfs constraint colocation add res_nfs-server-clone sharedFS-clone
# pcs cluster cib-push r_nfs
Filtrando el puerto 111
Al arrancar el servidor NFS estamos exponiendo el puerto 111 al exterior, lo que puede terminar en un ataque de denegación de servicio.
Para evitar este problema permitiremos el acceso a ese puerto solamente a las IPs de la red 192.168.100.0/24, que es la que hemos creado para conectar internamente las máquinas virtuales con los nodos. Empleamos iptables para este fin.
Sirva como guía esta entrada de los tutoriales.
En resumen lo que habría que hacer sería:
- Instalar iptables-services:
# yum install iptables-services
- Añadir las reglas:
# iptables -A INPUT -p tcp -s 192.168.100.0/24 --dport 111 -j ACCEPT
# iptables -A INPUT -p udp -s 192.168.100.0/24 --dport 111 -j ACCEPT
# iptables -A INPUT -p tcp --dport 111 -j DROP
# iptables -A INPUT -p udp --dport 111 -j DROP
- Guardar la configuración:
# iptables-save > /etc/sysconfig/iptables
- Habilitar iptables:
# systemctl enable iptables

